

It has been quite a time since we are hearing this term “Big Data” along with other terms such as Hadoop, MapReduce etc. Big Data for sure will become a widely used practice in the near future so, it is very important for you to have at least a basic understanding of the topic. So if you have travelled along tonnes of web pages and still cannot figure out “What the heck is Big Data?”, then you have landed on a correct page this time. By the end of this post, I guarantee you that you will understand this topic to the core so, have patience and stick till the end.

Big Data as the terms suggests is big in amount. It is the collection of an ever-growing data which is generated by the electronic and smart devices, social handles, websites and human interactivity with the smart devices. It is the data accumulated on multiple stacked servers in large data centres. This data is absolutely raw and unprocessed and thus, cannot be used for an analysis.
What is Hadoop?
Hadoop is a free programming framework based on the JAVA platform that supports large data sets processing in a distributed computing environment. It was created by Doug Cutting who named the framework after his child’s stuffed elephant toy. It is a sponsored project of the Apache Software Foundation.
Hadoop enables systems to be divided into smaller sections called as nodes. Each node involves the processing of thousands of terabytes of data. Thus, Hadoop is said to have a distributed file system popularly known as Hadoop fs in the industry. This distributed file system facilitates enormous data transfer rates among nodes thus allowing the system to run uninterrupted in the case of node failure. This lowers the risk of big system failures even if multiple nodes become inoperative.
The latest version of Hadoop is 2.7.2 as on 10th of May 2016. You can see the latest version of Hadoop and download Hadoop core jar files from the Hadoop website.
So now we a little idea about Big Data Hadoop definition. Let’s learn more about them.
How is Big Data different from Hadoop?
Big Data is an ambiguous term, an asset which is a collection of tonnes of subjects while Hadoop is a program or a process to deal with this large stack of an unprocessed collection of data. Hadoop is an open-source framework that is used to store and process big data in a distributed environment across various clusters of computers using easy programming models. It has been designed to map up data from single servers to tonnes of machines, each enabled with local computation and storage.
This may be hard to understand as of now. Let me give you an example to give you a basic idea of how Hadoop works on Big Data?
Let us take this Hadoop sort example:
Suppose, there are four members in the family – A,B,C and D. A has a blue colored toothbrush with soft bristles, B has a green colored toothbrush with hard bristles, C has an orange-colored toothbrush with soft bristles and D has a blue colored toothbrush with hard bristles.

So, now we have a collection of toothbrushes. Take this collection of toothbrushes as Big Data. Now comes an interesting situation. For a DNA analysis, the doctor wants A’s toothbrush. How will he find the correct toothbrush? He will apply an analysis program known as Hadoop on Big Data. Hadoop needs a key-value pair to traverse the data pool. So, here, Key will be the toothbrush and the Value will be a blue colored toothbrush with soft bristles. So A is the prime subject in the collection of four different subjects. First, the program will map the whole collection of toothbrushes, then it will apply the values one by one. In this case, the first value will be a blue colored toothbrush for which the Hadoop program will produce two results i.e. A and D (both have a blue colored toothbrush). The next value will be soft bristles for which the program will generate the final result i.e. the toothbrush of A.
This was just to give you a hint about the basic working of Hadoop on Big Data. In actual, this collection is too large to imagine and there are multiple key-value pairs which are applied one by one to get the resultant subject.
The Internet Of Things has a big relation with Big Data. I have already added a post on the Internet of Things where you can know more about it.
From traffic patterns and music video downloads to web history and healthcare records, data is being recorded, stored and analyzed to enable the technology and services that the whole world relies on every day. But what exactly is Big Data? How can these massive amounts of data be used? The IBM data scientists have identified Big Data in four dimensions:
- Volume
- Velocity
- Variety
- Veracity

The Volume signifies the probable data generated every day through the electronic and handheld devices. Although it is very difficult to predict the data which will be generated in a particular time frame. The following stats will give you a hint about the vastness and length of data that can be produced:
- Around 6 billion people already have cell phones. The world population is around 7 billion. Just imagine the data which will be generated majorly through the social networking sites itself.
- Most companies in the US have 100 Terabytes(1,00,000 Gigabytes) of data stored.
- It is estimated that around 2.8 Quintillion(2.3 Trillion Gigabytes) bytes of data is created each day.
- It is estimated that 41 zettabytes (43 Trillion Gigabytes) of data will be generated on the web by 2020.
Moving on to the next V of Big data i.e. Velocity. Velocity depicts the analysis of data that is currently being streamed on the web. The following picture will help you to give a clear idea about it.
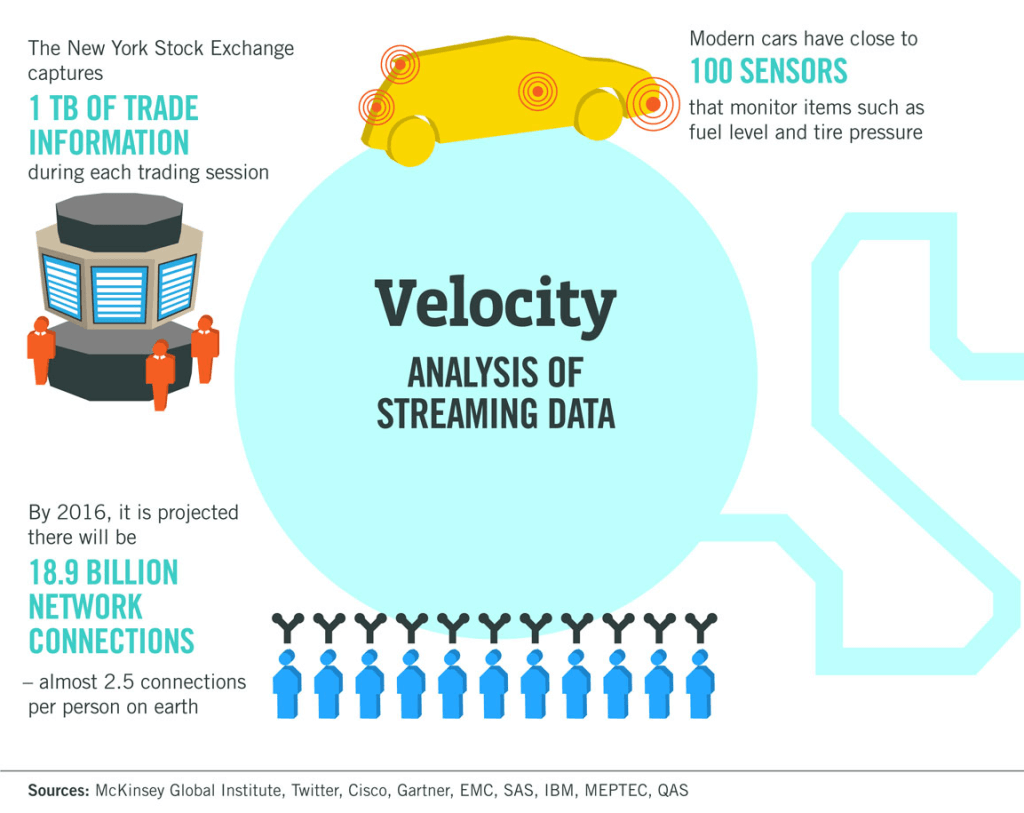

The third V of Big Data is Variety. As you know that data can be viewed in many ways. You can view data in text, visual, audio or infographics form. I like to view any info in text or in a video format. This way I can connect more with the information and understand the topic easily. So here are some figures and facts you should know:
- More than 100 hours of videos are uploaded to YouTube every minute.
- 40-50 billion pieces of content if being shared on Facebook every month.
- Around 500 million Tweets are sent by 200 million active Twitter users.
- By 2017, it is anticipated that there will be 500 million, wireless health monitors.
- As of 2016, the global size of data in healthcare is estimated to be near to 500 Exabytes.
The last V of Big Data is Veracity. The following picture by IBM clearly depicts the importance of data in the ongoing scenario.
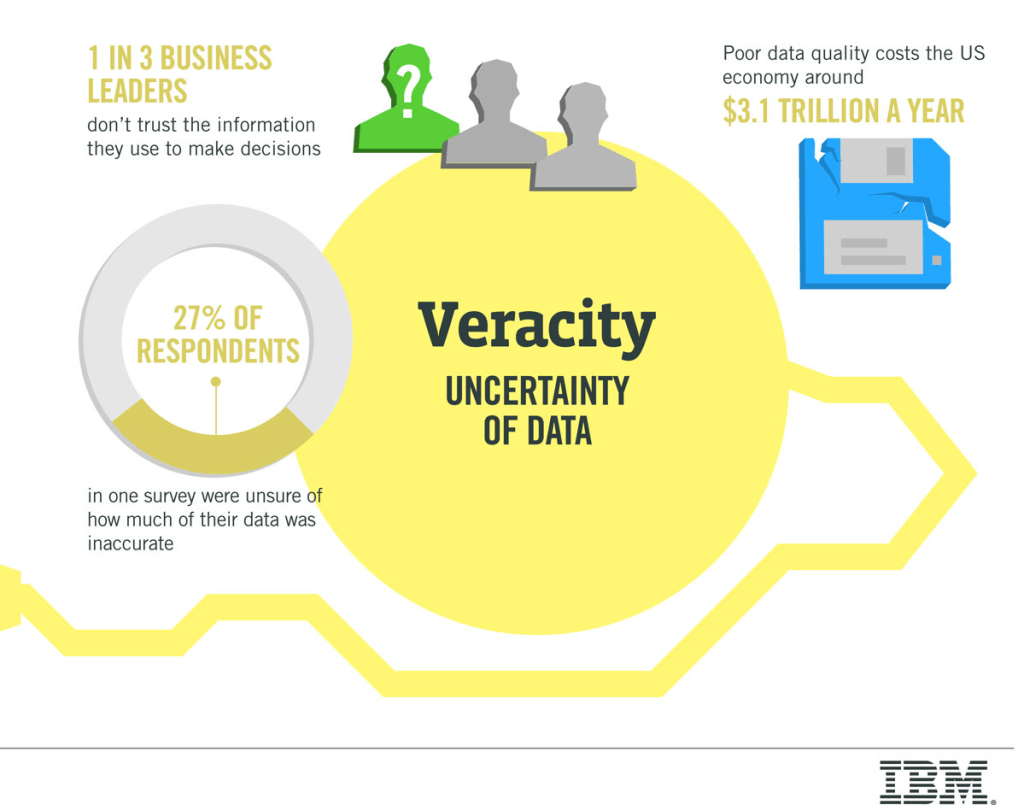
It is very important to extract useful data from a large heap. Data in raw form is of no use and various procedures of data mining and extraction is used to extract useful data i.e. information from the data set. Depending on the organization and industry, big data comprises information from various internal and external sources such as social media, transactions, enterprise content, electronic sensors and mobile devices. Companies can use data to adapt their products and services to better meet customer requirements, optimize operations and infrastructure, and generate new sources of revenue.
So , I’ve clearly elaborated the basics of Big Data and I hope you have understood the term so that you may or can implement it in your future projects or activities.
Feel free to share this post with your friends. As it is correctly said:
Knowledge only grows by sharing. You can only have more for yourself by giving it away to others.
Also read: Best cameras for YouTube videos



5 comments
Nice post bro!!!
Thanx Paras!!
Stay tuned for more!! 🙂
Very well explained
Wow !!
Thanks Ankit!!
Stay tuned for more!! 🙂
Nicely put together. Great work, keep up good work.